Restructure et regroupe les entités entrantes basées sur des entités individuelles selon les attributs spécifié dans Regrouper par et calcule le résumé statistique pour créer un tableau croisé dynamique en sortie.
Cas d'utilisation courants
- Calcul de statistiques basé sur des données tabulaires
Comment fonctionne-t-il ?
AttributePivoter reçoit des entités avec attributs, les restructure et les regroupe en se basant sur les attributs Regrouper par spécifiés, puis calcule des statistiques en se basant sur un attribut à analyser spécifié afin de générer un tableau croisé dynamique.
Comme StatisticsCalculator, AttributePivoter regroupe les entités en fonction des attributs sélectionnés et calcule des statistiques sur un seul attribut pour toutes les entités de chaque groupe (regroupement par rangées). En outre, AttributePivoter permet de spécifier l'ordre de ces attributs de regroupement par rangée afin de générer une imbrication logique de rangées de résumé supplémentaires. AttributePivoter permet également de générer dynamiquement de nouveaux attributs sur la base des valeurs uniques d'un attribut sélectionné (regroupement par colonne), avec des valeurs alimentées par les statistiques réalisées sur les regroupements résultants.
Note: AttributePivoter génère les attributs dynamiquement, vous devez donc définir les types d'entités destination en mode dynamique si vous souhaitez inclure ces attributs en destination. Ceci est décrit plus en détail dans la section Regroupement des résultats et structure tabulaire.
Regrouper les lignes par et (optionnellement) Regrouper les colonnes par définissent une imbrication logique de groupes de lignes.
Pour chacun de ces groupes logiquement imbriqués, l'AttributePivoter calcule des statistiques récapitulatives, qu'il émet sous forme de lignes de tableau via le port Summary. La valeur de la ligne de synthèse calculée est définie par <attrName><description>, où <attrName> est le nom de l'attribut de regroupement et <description> est la valeur fournie dans le paramètre 'Description des lignes de synthèse'.
Par exemple, dans le cas d'un regroupement selon l'attribut "Region_RSS", la ligne synthétisant toutes les régions aura pour valeur "Region_RSS Total" pour l'attribut "Region_RSS", à condition que la description des lignes de synthèse soit sur la valeur par défaut de "Total".
Les entités sont regroupées selon un attribut de regroupement et des statistiques sont calculées, pour chaque groupe, selon un attribut défini en paramètre. Il existe deux types d'attributs de regroupement qui fonctionnent ensemble pour définir ces groupes :
- Attributs de regroupement en lignes : L'utilisateur spécifie un ensemble ordonné d'attributs qui divisent les statistiques en rangées. Il y a une seule ligne de données de résultat pour chaque ensemble unique de valeurs pour l'ensemble spécifié d'attributs de regroupement de lignes.
- Attribut de regroupement de colonnes : L'utilisateur peut éventuellement spécifier un attribut unique pour définir les colonnes dans les lignes résultantes. S'il est spécifié, chaque valeur unique de l'attribut de regroupement de colonnes apporte une colonne de données statistiques au résultat, pour chaque statistique calculée. De plus, s'il y a plus d'une valeur unique pour la colonne, une colonne de résumé sera générée pour chaque statistique.
Si aucun attribut de regroupement n'est sélectionné, chaque ligne contiendra un unique résultat.
Les attributs de regroupement des lignes étant ordonnés, ils effectuent une imbrication logique des groupes. Au niveau le plus bas, un ensemble complet de valeurs uniques est représenté par une seule ligne du résultat. Un niveau plus haut se trouve le groupement logique constitué de l'ensemble des lignes pour lesquelles tous les attributs de groupement de lignes sont uniques, à l'exception de la dernière ligne spécifiée. Cette imbrication logique se poursuit jusqu'aux premiers attributs de regroupement de lignes spécifiés.
Une ligne résultant d'un ensemble complet de valeurs de données uniques est appelée "ligne de données". Une "ligne de résumé" supplémentaire est générée pour chaque regroupement logiquement imbriqué, qui résume les données des lignes de données contenues dans le regroupement.
Les lignes forment un tableau avec les attributs suivants :
- Tous les attributs de regroupement de lignes dont les valeurs combinées déterminent le groupe
- Pour chaque type de résumé pivot, un attribut avec des statistiques correspondants, est calculé à partir de toutes les entités du groupe ligne.
- Si plus d'un groupe de colonnes a été défini, chacun des attributs de (2.) sera répété pour tous les groupes de colonnes, ainsi qu'une valeur récapitulative (c'est-à-dire un "grand total") calculée sur les valeurs des attributs de tous les groupes de colonnes. La méthode de calcul de la valeur récapitulative dépend de la statistique qu'elle représente :
- Les statistiques Count (compte) et Sum (somme) sont synthétisées s avec la somme des statistiques calculées pour le groupe de lignes.
- Average (moyenne) correspond à la moyenne de toutes les valeurs de chaque groupe de lignes.
- Les valeurs Min correspondent aux valeurs minimales de l'attribut analysé de chaque groupe de lignes.
- Les valeurs Max correspondent aux valeurs maximales de l'attribut analysé de chaque groupe de lignes.
Les premières entités et les premières statistiques émises contiennent des attributs supplémentaires comportant des informations de schéma nécessaires pour écrire les données dans le cadre d'un schéma dynamique.
Exemples
Dans cet exemple, nous partons d'un simple tableau CSV de statistiques à faire pivoter et à analyser. Les entités CSV sont acheminées dans un AttributePivoter.
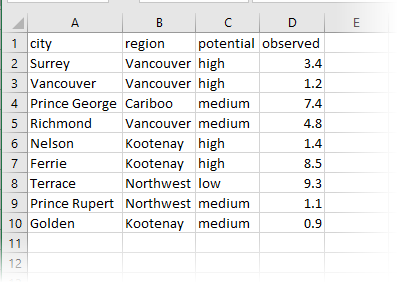
Dans la boîte de dialogue des paramètres, nous choisissons de regrouper les lignes par région, puis par potentiel. L'ordre est important.
L'attribut à analyser est observed - la colonne contenant nos statistiques. Nous avons demandé des calculs de Compte, de Somme et de Moyenne.

La sortie (via un Writer Excel dynamique) contient maintenant les statistiques ajoutées.
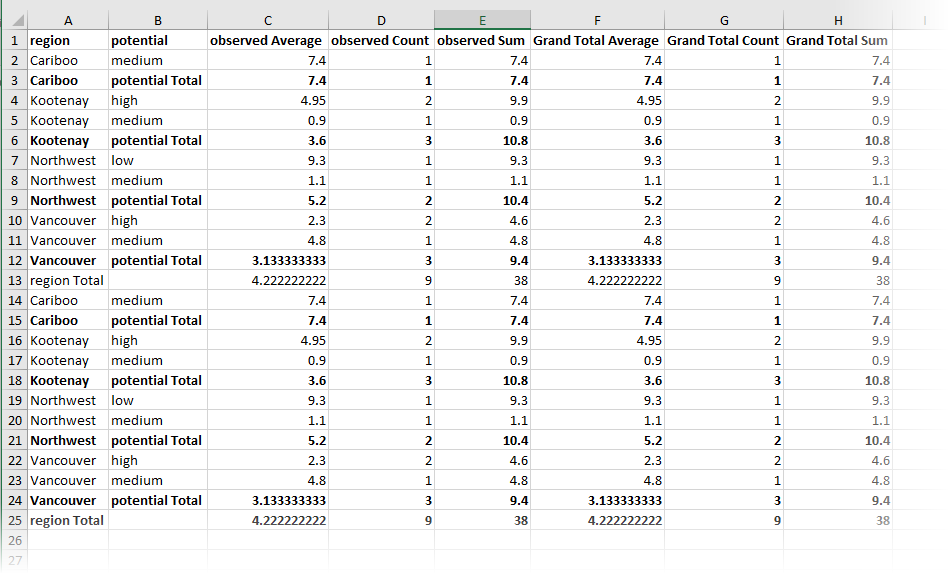
Notes
- AttributePivoter ne peut être utilisé que pour analyser un seul attribut à la fois. Si vous devez analyser plus d'un attribut, envisagez l'option StatisticsCalculator.
Configuration
Ports d'entrée
Entités avec des attributs à analyser.
Ports de sortie
Une seule nouvelle entité sera produite, contenant toutes les statistiques calculées pour chaque groupe de lignes complètement défini. Les attributs de ces entités sont décrits dans la section "Regroupement des résultats et structure tabulaire".
La première ligne sortant du port DATA contient les informations relatives aux types d'entités définies par le schéma dynamique.
Pour chaque regroupement logiquement imbriqué tel que décrit dans la section "Regroupement des résultats et structure tabulaire", une ligne de résumé sera émise avant la première ligne de données du groupe. Elle fournit des informations récapitulatives pour toutes les rangées contenues dans le groupe. Un résumé de toutes les lignes sera toujours généré.
La première ligne sortant du port Summary contient les informations relatives au schéma pour une configuration dynamique.
Paramètres
|
Regroupement de lignes par |
Un ou plusieurs attributs sont choisis pour spécifier comment les entités sont regroupées pour former les lignes du tableau résultant. Contrairement à la plupart des paramètres "Regrouper par", l'utilisateur a la possibilité de spécifier l'ordre des attributs de regroupement, de sorte que des regroupements sommaires imbriqués peuvent être générés, ajoutant une structure hiérarchique au tableau résultant. |
|
Regroupement de colonnes par |
Optionnel : l'utilisateur peut également sélectionner un attribut dont les valeurs uniques généreront de nouveaux attributs, de sorte à "pivoter" les données et subdiviser les groupes de calcul de statistiques. |
|
Attributs à analyser |
Un seul attribut est choisi pour le calcul des statistiques. Les entités sont regroupées selon les attributs de regroupement des lignes et des colonnes, et les statistiques sont calculées sur toutes les valeurs de cet attribut dans les entités de chaque groupe. |
|
Type de statistiques de synthèse |
L'utilisateur peut choisir de calculer plusieurs types de statistiques récapitulatives simultanément. Chaque type de statistique sera représenté dans une colonne spécifique et ceci, dans chaque groupe défini en paramètre. Une ou plusieurs statistiques peuvent être calculées.
|
|
Description des lignes de synthèse |
Entrer un nom pour la ligne de synthèse de chaque groupe de lignes. Le descripteur par défaut est Total. |
Éditer les paramètres des Transformers
À l'aide d'un ensemble d'options de menu, les paramètres du Transformer peuvent être attribués en faisant référence à d'autres éléments de traitement. Des fonctions plus avancées, telles qu'un éditeur avancé et un éditeur arithmétique, sont également disponibles dans certains Transformers. Pour accéder à un menu de ces options, cliquez sur  à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
Définir les valeurs
Il existe plusieurs façons de définir une valeur à utiliser dans un Transformer. La plus simple est de simplement taper une valeur ou une chaîne de caractères, qui peut inclure des fonctions de différents types comme des références d'attributs, des fonctions mathématiques et de chaînes de caractères, et des paramètres de traitement. Il existe un certain nombre d'outils et de raccourcis qui peuvent aider à construire des valeurs, généralement disponibles dans le menu contextuel déroulant adjacent au champ de valeur.
Utilisation de l'éditeur de texte
L'éditeur de texte fournit un moyen efficace de construire des chaînes de textes (dont les expressions régulières) à partir de données source diverses, telles que des attributs, des paramètres et des constantes, et le résultat est directement utilisé dans le paramètre.
Utilisation de l'éditeur arithmétique
L'éditeur arithmétique fournit un moyen simple de construire des expressions mathématiques à partir de plusieurs données source, telles que des attributs et des fonctions, et le résultat est directement utilisé dans un paramètre.
Valeur conditionnelle
Définit des valeurs selon un ou plusieurs tests.
Fenêtre de définition de conditions
Contenu
Les expressions et chaînes de caractères peuvent inclure des fonctions, caractères, paramètres et plus.
Lors du paramétrage des valeurs - qu'elles soient entrées directement dans un paramètre ou construites en utilisant l'un des éditeurs - les chaînes de caractères et les expressions contenant des fonctions Chaîne de caractères, Math, Date et heure ou Entité FME auront ces fonctions évaluées. Par conséquent, les noms de ces fonctions (sous la forme @<nom_de_fonction>) ne doivent pas être utilisés comme valeurs littérales de chaîne de caractères.
| Ces fonctions manipulent les chaînes de caractères. | |
|
Caractères spéciaux |
Un ensemble de caractères de contrôle est disponible dans l'éditeur de texte. |
| Plusieurs fonctions sont disponibles dans les deux éditeurs. | |
| Fonctions Date/heure | Les fonctions de dates et heures sont disponibles dans l'Editeur texte. |
| Ces opérateur sont disponibles dans l'éditeur arithmétique. | |
| Elles retournent des valeurs spécifiques aux entités. | |
| Les paramètres FME et spécifiques au traitement peuvent être utilisés. | |
| Créer et modifier un paramètre publié | Créer ses propres paramètres éditables. |
Options - Tables
Les Transformers avec des paramètres de style table possèdent des outils additionnels pour remplir et manipuler des valeurs.
|
Réordonner
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
|
|
Couper, Copier et Coller
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
Copier, copier et coller peuvent être utilisés au sein d'un Transformer ou entre Transfromers. |
|
Filtre
|
Commencez à taper une chaîne de caractères, et la matrice n'affichera que les lignes correspondant à ces caractères. Recherche dans toutes les colonnes. Cela n'affecte que l'affichage des attributs dans le Transformer - cela ne change pas les attributs qui sont sortis. |
|
Importer
|
Le bouton d'import remplit la table avec un jeu de nouveaux attributs lus depuis un jeu de données. L'application spécifique varie selon les Transformers. |
|
Réinitialiser/Rafraîchir
|
Réinitialise la table à son état initial, et peut fournir des options additionnelles pour supprimer des entrées invalides. Le comportement varie d'un Transformer à l'autre. |




Note : Tous les outils ne sont pas disponibles dans tous les Transformers.
Références
|
Comportement |
|
|
Stockage des entités |
Oui |
| Dépendances | Aucun |
| Alias | |
| Historique |
FME Community
FME Community est l'endroit où trouver des démos, des tutoriaux, des articles, des FAQ et bien plus encore. Obtenez des réponses à vos questions, apprenez des autres utilisateurs et suggérez, votez et commentez de nouvelles entités.
Voir tous les résultats à propos de ce Transformer sur FME Community.
Les exemples peuvent contenir des informations sous licence Open Government - Vancouver et/ou Open Government - Canada.