Calcule les flux primaires et secondaires de réseaux à flux multiples. La clé pour déterminer la priorité est l'algorithme du plus court chemin utilisant des itérations multiples dans un graphe de réseau.
Cet attribut définit, pour chaque jonction source du réseau, un chemin unique (le plus court chemin) pour atteindre la jonction de destination. Toutes les lignes de flux incluses dans un chemin (des sources à la destination) auront un attribut de priorité de flux défini sur 1 (primaire) ; toutes les autres sont définies sur 2 (secondaire).
Pour utiliser ce Transformer, vous aurez besoin de spécifier le poids des lignes du réseau en spécifiant l’Attributs de Poids en avant et éventuellement l’attribut de Poids inversé si le graphe du réseau est non orienté.
Un poids est une propriété d'une ligne de réseau généralement utilisée pour représenter un coût de traversée d'une ligne de réseau. Un exemple de poids de ligne est la longueur de la ligne. Dans une analyse du plus court chemin, vous choisirez ce poids si vous voulez que le chemin résultant soit de la plus courte longueur. Pour les entités de ligne, 2 poids peuvent être utilisés : un dans la direction numérisée de l'entité de ligne (le poids avant) et un contre la direction numérisée de l'entité de ligne (le poids arrière). La direction numérisée d'une entité linéaire fait référence à l'ordre des sommets.
L'objectif est de signaler les boucles (cycles) dans le réseau afin de faire ressortir les lignes du réseau primaire.
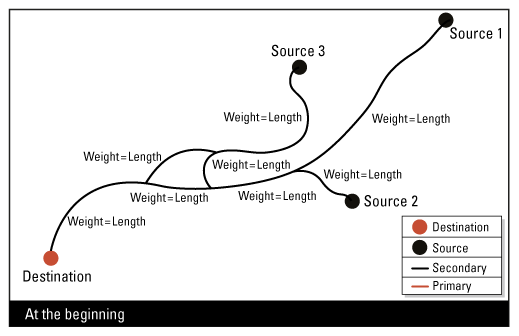
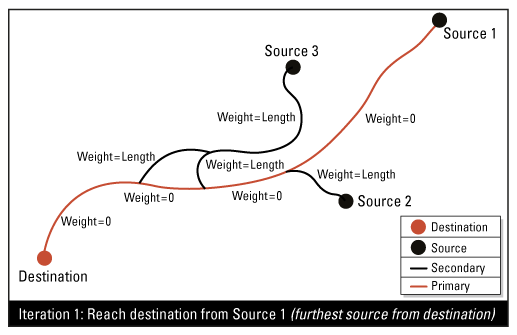
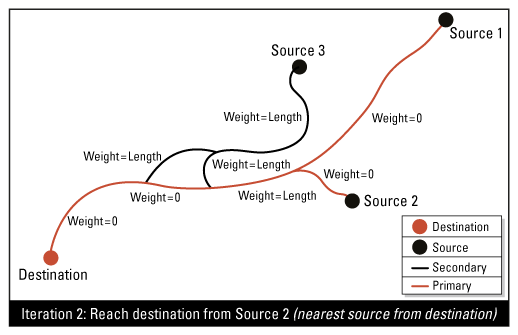
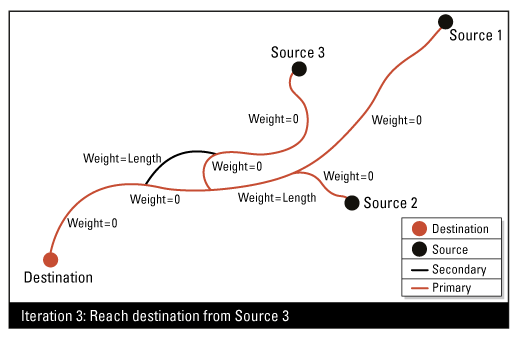
Résultats attendus
- Lignes du réseau avec un attribut de priorité de flux défini sur 1 (primaire) ou 2 (secondaire). S'il n'est pas possible de déterminer la priorité (s'il n'y a pas de destination située sur le graphe du réseau), un attribut de priorité de flux est défini à -1. Les lignes du réseau ont également un attribut Graph Identifier. Toutes les lignes du réseau d'un même graphe auront la même valeur dans cet attribut.
- Destination inutilisée (si la destination n'est pas située sur un point terminal du graphe de réseau).
Exemples
Ce Transformer peut être utilisé sur les lignes de flux linéaires du réseau. Il existe deux façons de déterminer l'attribut de priorité du flux :
- Pour calculer l'attribut de priorité du flux pour les lignes de réseau orientées : pour ces lignes, la direction numérisées représente une direction de l'écoulement en aval.
- Pour calculer l'attribut de priorité du flux pour les lignes de réseau non-orientées : pour ces lignes, la direction numérisée n'est pas significative.
Calcul de la priorité pour les lignes orientées du réseau
Lorsque les lignes du réseau sont orientées, le plus court chemin ne doit pas aller à l'encontre de la direction numérisée. Ainsi, initialement le poids le long de la direction numérisée (le poids avant) est la longueur, et le poids contre la direction numérisée (le poids arrière) est une valeur plus grande.
Notons que le poids inverse est optionnel et n'est généralement pas nécessaire.
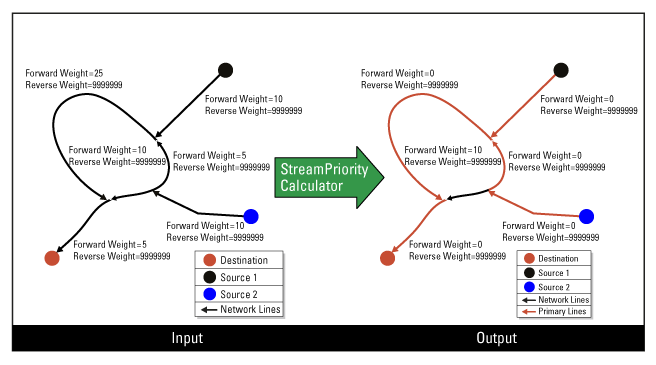
Calcul de la priorité pour les lignes non orientées du réseau
Lorsque les lignes du réseau ne sont pas orientées, la direction numérisée des lignes du réseau n'est pas significative. Ainsi, le poids le long de la direction numérisée (poids avant) et le poids contre la direction numérisée (poids arrière) sont les mêmes. Dans ce cas, vous pouvez utiliser le même attribut correspondant à la longueur pour les deux paramètres de poids. De cette façon, les boucles sont supprimées pour les lignes du réseau primaire (priorité du flux = 1) et vous pouvez appliquer d'autres algorithmes pour modifier la direction numérisée. C'est ainsi que vous pouvez rendre les lignes du réseau primaires (priorité de flux = 1) où la direction numérisée représente une direction de flux en aval.

Configuration
Ports en entrée
Lignes du réseau avec des cycles (boucles).
Les nœuds de destination, situés sur un point d'extrémité (feuille) du graphe du réseau. Tous les autres points d'extrémité du graphe du réseau sont considérés comme des sources.
Ports de sortie
Les flux qui sont connectées entre-elles se verront attribuer la même valeur pour l’attribut réseau ID.
Un seul nœud de destination est autorisé par réseau. Tout nœud de destination supplémentaire trouvé est émis par le port ExtraDestination.
Les nœuds de destination qui ne sont trouvés sur aucun réseau sont émis via le port Invalid. Toutes les entités non linéaires sont également émises via le port Invalid.
Paramètres
|
Regrouper par |
Le comportement par défaut consiste à utiliser l'ensemble des entités d'entrée comme groupe. Cette option vous permet de sélectionner les attributs qui définissent les groupes à former. Chaque ensemble d'entités ayant la même valeur pour tous ces attributs sera traité comme un groupe indépendant. |
||||
|
Traitement des regroupements |
Sélectionnez le moment du traitement où les groupes sont traités :
Il y a deux raisons typiques d'utiliser Quand le groupe change (avancé). La première concerne les données entrantes qui sont destinées à être traitées en groupes (et qui sont déjà classées ainsi). Dans ce cas, c'est la structure qui dicte l'utilisation de Regrouper par - et non des considérations de performance. La seconde raison possible est le potentiel gain de performances. Les gains de performance sont plus visibles quand les données sont déjà triées (ou lues en utilisant une déclaration SQL ORDER BY) puisque moins de travail est requis de la part de FME. Si les données doivent être ordonnées, elles peuvent être triées dans le traitement (bien que la surcharge de traitement supplémentaire puisse annuler tout gain). Le tri devient plus difficile en fonction du nombre de flux de données. Il peut être quasiment impossible de trier des flux de données multiples dans l'ordre correct, car toutes les entités correspondant à une valeur Regrouper par doivent arriver avant toute entité (de tout type d'entité ou jeu de données) appartenant au groupe suivant. Dans ce cas, l'utilisation de Regrouper par avec Lorsque toutes les entités sont reçues peut être une approche équivalente et plus simple. De multiples types d'entités et entités de multiples jeux de données ne vont généralement pas arriver dans l'ordre correct. Comme pour beaucoup de scénarios, tester différentes approches dans votre traitement avec vos données est le seul moyen sûr d'identifier le gain de performance. |
|
Attribut Poids en avant |
Un nom d'attribut sur les lignes du réseau qui contient un poids le long de la direction numérisée. Ce paramètre est nécessaire pour appliquer l'algorithme du plus court chemin. |
|
Attribut Poids Inversé |
Un nom d'attribut sur les lignes du réseau qui contient un poids par rapport à la direction numérisée. Ce paramètre est nécessaire pour appliquer l'algorithme du plus court chemin si la direction numérisée des lignes du réseau est significative. Par exemple, la direction numérisée peut représenter une direction d'écoulement en aval pour un réseau hydrographique. Si la direction numérisée n'est pas significative pour un graphe de réseau, un utilisateur peut fournir le même attribut du paramètre Attribut de poids en avant. |
|
ID réseau |
Les flux qui sont connectés se verront attribuer le même ID de réseau dans l'attribut ID réseau. Tous les flux se verront attribuer une valeur de priorité de flux dans l'attribut Priorité de flux soit -1, 1 ou 2. Les flux qui ne sont pas connectés aux nœuds de destination se verront attribuer une valeur de priorité de niveau -1. Parallèlement, les flux primaires ou secondaires se verront attribuer une valeur de priorité de niveau 1 ou 2 respectivement. |
|
Priorité de flux |
Nommez l'attribut qui contient la valeur de priorité du flux (1 pour primaire ou 2 pour secondaire) pour les lignes de réseau de sortie. |
Éditer les paramètres des Transformers
À l'aide d'un ensemble d'options de menu, les paramètres du Transformer peuvent être attribués en faisant référence à d'autres éléments de traitement. Des fonctions plus avancées, telles qu'un éditeur avancé et un éditeur arithmétique, sont également disponibles dans certains Transformers. Pour accéder à un menu de ces options, cliquez sur  à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
Définir les valeurs
Il existe plusieurs façons de définir une valeur à utiliser dans un Transformer. La plus simple est de simplement taper une valeur ou une chaîne de caractères, qui peut inclure des fonctions de différents types comme des références d'attributs, des fonctions mathématiques et de chaînes de caractères, et des paramètres de traitement. Il existe un certain nombre d'outils et de raccourcis qui peuvent aider à construire des valeurs, généralement disponibles dans le menu contextuel déroulant adjacent au champ de valeur.
Utilisation de l'éditeur de texte
L'éditeur de texte fournit un moyen efficace de construire des chaînes de textes (dont les expressions régulières) à partir de données source diverses, telles que des attributs, des paramètres et des constantes, et le résultat est directement utilisé dans le paramètre.
Utilisation de l'éditeur arithmétique
L'éditeur arithmétique fournit un moyen simple de construire des expressions mathématiques à partir de plusieurs données source, telles que des attributs et des fonctions, et le résultat est directement utilisé dans un paramètre.
Valeur conditionnelle
Définit des valeurs selon un ou plusieurs tests.
Fenêtre de définition de conditions
Contenu
Les expressions et chaînes de caractères peuvent inclure des fonctions, caractères, paramètres et plus.
Lors du paramétrage des valeurs - qu'elles soient entrées directement dans un paramètre ou construites en utilisant l'un des éditeurs - les chaînes de caractères et les expressions contenant des fonctions Chaîne de caractères, Math, Date et heure ou Entité FME auront ces fonctions évaluées. Par conséquent, les noms de ces fonctions (sous la forme @<nom_de_fonction>) ne doivent pas être utilisés comme valeurs littérales de chaîne de caractères.
| Ces fonctions manipulent les chaînes de caractères. | |
|
Caractères spéciaux |
Un ensemble de caractères de contrôle est disponible dans l'éditeur de texte. |
| Plusieurs fonctions sont disponibles dans les deux éditeurs. | |
| Fonctions Date/heure | Les fonctions de dates et heures sont disponibles dans l'Editeur texte. |
| Ces opérateur sont disponibles dans l'éditeur arithmétique. | |
| Elles retournent des valeurs spécifiques aux entités. | |
| Les paramètres FME et spécifiques au traitement peuvent être utilisés. | |
| Créer et modifier un paramètre publié | Créer ses propres paramètres éditables. |
Options - Tables
Les Transformers avec des paramètres de style table possèdent des outils additionnels pour remplir et manipuler des valeurs.
|
Réordonner
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
|
|
Couper, Copier et Coller
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
Copier, copier et coller peuvent être utilisés au sein d'un Transformer ou entre Transfromers. |
|
Filtre
|
Commencez à taper une chaîne de caractères, et la matrice n'affichera que les lignes correspondant à ces caractères. Recherche dans toutes les colonnes. Cela n'affecte que l'affichage des attributs dans le Transformer - cela ne change pas les attributs qui sont sortis. |
|
Importer
|
Le bouton d'import remplit la table avec un jeu de nouveaux attributs lus depuis un jeu de données. L'application spécifique varie selon les Transformers. |
|
Réinitialiser/Rafraîchir
|
Réinitialise la table à son état initial, et peut fournir des options additionnelles pour supprimer des entrées invalides. Le comportement varie d'un Transformer à l'autre. |




Note : Tous les outils ne sont pas disponibles dans tous les Transformers.
FME Community
FME Community est l'endroit où trouver des démos, des tutoriaux, des articles, des FAQ et bien plus encore. Obtenez des réponses à vos questions, apprenez des autres utilisateurs et suggérez, votez et commentez de nouvelles entités.
Voir tous les résultats à propos de ce Transformer sur FME Community.
Mots clefs : LevelPriorityCalculator