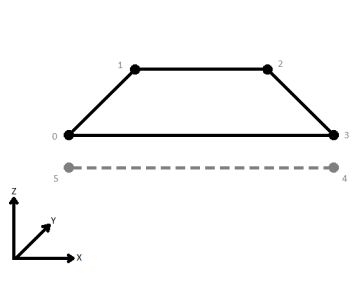
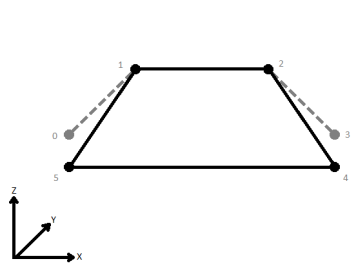
Dissout les entités surfaciques en supprimant les limites communes pour créer des zones plus grandes. Les attributs d'entrée peuvent être accumulés.
L'entrée agrégée sera désagrégée par le Transformer. Les attributs de l'entité agrégée seront propagés à ses parties.
Puisque les agrégats sont désagrégés dans le Dissolver, il est possible que le nombre d'entités générées soit plus important que le nombre d'entités entrantes dans le Transformer.
Les polygones dissous sont formés quand des sommets communs entre polygones adjacents sont supprimés.
Exemples
L'exemple ci-dessous illustre des polygones avant et après que Dissolver ait été utilisé.
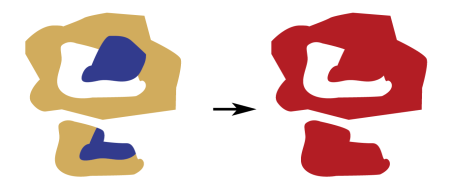
Configuration
Ports d'entrée
Ce Transformer accepte les entités polygonales bidimensionnelles, y compris les polygones troués. Ces entités polygonales sont généralement appelées des polygones.
Ports de sortie
Entités surfaciques dissoutes avec des attributs spécifiés.
Géométries et attributs qui sont laissés après dissolution.
Si le fme_remnant_type est INTERIOR_LINE, ce reste est une entité linéaire qui représente les portions des polygones en entrée qui ne font pas partie du polygone dissous en sortie car l'entité linéaire était soit colinéaire avec une autre entité soit à l'intérieur d'une région superposée.
Si le type fme_remnant_type est UNUSED_DATA, ce reste est une entité qui contient les données d'entrée restantes qui ne faisaient pas partie de la sortie dissoute. Si l'entité restante a une géométrie, cette géométrie n'a pas été utilisée dans la sortie. Si l'entité restante n'a pas de géométrie, cette entité contient les attributs qui n'ont pas été utilisés dans la sortie.
Les entités non surfaciques ressortent par ce port.
Paramètres
|
Regrouper par |
Les entités polygonales d'entrée peuvent être divisées en groupes pour être dissoutes en utilisant le paramètre Regrouper par. Si ce paramètre n'est pas spécifié, toutes les entités d'entrée sont traitées ensemble. Le paramètre Regrouper par permet à une seule usine de dissoudre plusieurs ensembles de polygones potentiellement superposés. |
||||
|
Traitement des regroupements |
Sélectionnez le moment du traitement où les groupes sont traités :
Il y a deux raisons typiques d'utiliser Quand le groupe change (avancé). La première concerne les données entrantes qui sont destinées à être traitées en groupes (et qui sont déjà classées ainsi). Dans ce cas, c'est la structure qui dicte l'utilisation de Regrouper par - et non des considérations de performance. La seconde raison possible est le potentiel gain de performances. Les gains de performance sont plus visibles quand les données sont déjà triées (ou lues en utilisant une déclaration SQL ORDER BY) puisque moins de travail est requis de la part de FME. Si les données doivent être ordonnées, elles peuvent être triées dans le traitement (bien que la surcharge de traitement supplémentaire puisse annuler tout gain). Le tri devient plus difficile en fonction du nombre de flux de données. Il peut être quasiment impossible de trier des flux de données multiples dans l'ordre correct, car toutes les entités correspondant à une valeur Regrouper par doivent arriver avant toute entité (de tout type d'entité ou jeu de données) appartenant au groupe suivant. Dans ce cas, l'utilisation de Regrouper par avec Lorsque toutes les entités sont reçues peut être une approche équivalente et plus simple. Note De multiples types d'entités et entités de multiples jeux de données ne vont généralement pas arriver dans l'ordre correct.
Comme pour beaucoup de scénarios, tester différentes approches dans votre traitement avec vos données est le seul moyen sûr d'identifier le gain de performance. |
|
Tolérance |
La distance minimale entre les géométries en 2D avant qu'elles ne soient considérées comme égales, en unités terrestres. Si la tolérance est Automatique, une tolérance sera automatiquement calculée en fonction de l'emplacement des géométries d'entrée. En outre, une tolérance personnalisée peut être utilisée. |
||||||||||||||||||
|
Méthode de connexion du Z |
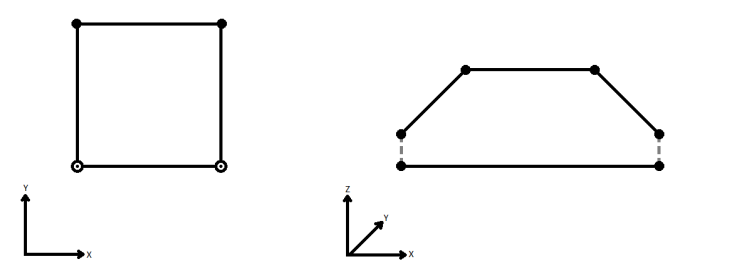
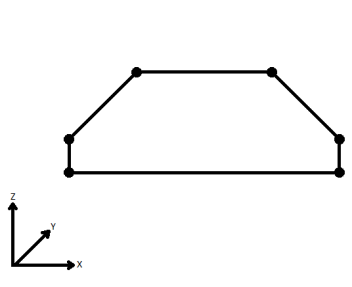
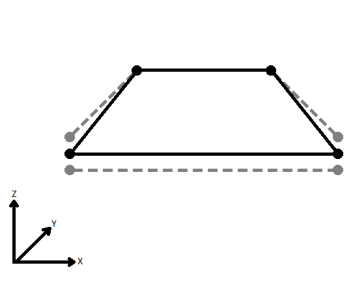
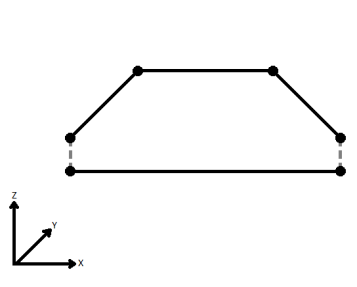
Si applicable, sélectionner une méthode pour la gestion des valeurs z. En le visualisant en 2D (en ignorant le Z), un chemin (qui peut définir le bord d'un polygone) peut apparaître fermé tel que montré ci-dessous. Ce même chemin, vu en 3D, peut apparaître ouvert comme le montre la figure de droite ci-dessous.
Pour spécifier la façon (et si) dont le chemin doit être fermé en 3D, sélectionner une des méthodes suivantes.
|
||||||||||||||||||
|
Gestion des agrégats |
Choisir comment les agrégats de géométries doivent être gérés. Désagréger : Décompose les agrégats en leurs composants individuels. Avec ce paramètre, le Transformer peut produire plus d'entités que celles qui ont été données en entrée. Rejeter : ne pas traiter les agrégats et les sortir via le port <Rejected>. |
|
Traitement des attributs |
Spécifie comment les attributs doivent être accumulés. Si l'option Supprimer les attributs est sélectionnée, tous les attributs entrants sont supprimés des entités. Utiliser les attributs d'une entité prend tous les attributs de la plus grande entité source. Regrouper les attributs fusionne tous les attributs des segments qui se chevauchent. S'il y a des conflits, les attributs des polygones d'entrée seront préservés dans un processus en deux étapes :
|
|
Attributs à sommer |
Tous les attributs renseignés dans ce paramètre feront l'objet de statistiques. Par exemple, si deux polygones en entrée ont un attribut "prix" de 3000 et 50000, le polygone agrégé en sortie aura un attribut "prix" de 8000. |
|
Attribut(s) à moyenner |
Tous les attributs renseignés dans ce paramètre feront l'objet de statistiques. Par exemple, si deux polygones en entrée ont un attribut "prix" de 30000 et 50000, le polygone agrégé en sortie aura un attribut "prix" de 40000. |
|
Attributs à moyenner pondérés par la surface |
Tous les attributs renseignés dans ce paramètre feront l'objet de statistiques. Par exemple, si deux polygones en entrée ont respectivement un attribut "prix" de 30000 et de 50000, et si le second polygone est 3 fois plus grand que le premier polygone, alors la moyenne pondérée sera de 45000. attributs à moyenner et les attributs à moyenner pondérés par la surface peuvent produire des résultats non numériques si certaines entités en entrée ont un zéro ou aucune superficie. |
Génération de liste
Lorsqu'il est activé, ajoute un attribut de liste dans lequel les attributs des entités d'entrée sont stockés. Les attributs de l'entité ayant la plus grande surface sont stockés en tête de liste, et aucun ordre n'est défini pour les autres éléments.
Par exemple, si 3 polygones en entrée sont dissous en 1, alors ce dernier aura une liste de 3 éléments, chacun contenant l'ensemble des attributs des 3 polygones entrants.
|
Liste |
Entrer un nom de liste. Note Les attributs de liste ne sont pas accessibles à partir du schéma de sortie dans FME Workbench, sauf s'ils sont d'abord traités à l'aide d'un Transformer qui opère sur eux, comme ListExploder ou ListConcatenator. Il est également possible d'utiliser AttributeExposer.
|
|
Ajouter à la liste |
Tous les attributs : tous les attributs des entités entrantes ayant généré des entités en sortie seront ajoutés à la liste spécifiée dans le paramètre Liste. Attributs sélectionnés : seuls les attributs spécifiés dans le paramètre Attributs sélectionnés seront ajoutés à la liste spécifiée dans le paramètre Liste. |
|
Attributs sélectionnés |
Les attributs à ajouter à la liste lorsque le paramètre Ajouter à la liste vaut Attributs sélectionné. |
|
Nombre de dissolutions |
Nommez l'attribut qui contient le nombre de polygones d'entrée dissous dans un polygone de sortie. Par exemple, si 3 polygones sont dissous en 1, alors le polygone généré aura cet attribut défini à 3. |
Éditer les paramètres des Transformers
À l'aide d'un ensemble d'options de menu, les paramètres du Transformer peuvent être attribués en faisant référence à d'autres éléments de traitement. Des fonctions plus avancées, telles qu'un éditeur avancé et un éditeur arithmétique, sont également disponibles dans certains Transformers. Pour accéder à un menu de ces options, cliquez sur  à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
Définir les valeurs
Il existe plusieurs façons de définir une valeur à utiliser dans un Transformer. La plus simple est de simplement taper une valeur ou une chaîne de caractères, qui peut inclure des fonctions de différents types comme des références d'attributs, des fonctions mathématiques et de chaînes de caractères, et des paramètres de traitement. Il existe un certain nombre d'outils et de raccourcis qui peuvent aider à construire des valeurs, généralement disponibles dans le menu contextuel déroulant adjacent au champ de valeur.
Utilisation de l'éditeur de texte
L'éditeur de texte fournit un moyen efficace de construire des chaînes de textes (dont les expressions régulières) à partir de données source diverses, telles que des attributs, des paramètres et des constantes, et le résultat est directement utilisé dans le paramètre.
Utilisation de l'éditeur arithmétique
L'éditeur arithmétique fournit un moyen simple de construire des expressions mathématiques à partir de plusieurs données source, telles que des attributs et des fonctions, et le résultat est directement utilisé dans un paramètre.
Valeur conditionnelle
Définit des valeurs selon un ou plusieurs tests.
Fenêtre de définition de conditions
Contenu
Les expressions et chaînes de caractères peuvent inclure des fonctions, caractères, paramètres et plus.
Lors du paramétrage des valeurs - qu'elles soient entrées directement dans un paramètre ou construites en utilisant l'un des éditeurs - les chaînes de caractères et les expressions contenant des fonctions Chaîne de caractères, Math, Date et heure ou Entité FME auront ces fonctions évaluées. Par conséquent, les noms de ces fonctions (sous la forme @<nom_de_fonction>) ne doivent pas être utilisés comme valeurs littérales de chaîne de caractères.
| Ces fonctions manipulent les chaînes de caractères. | |
|
Caractères spéciaux |
Un ensemble de caractères de contrôle est disponible dans l'éditeur de texte. |
| Plusieurs fonctions sont disponibles dans les deux éditeurs. | |
| Fonctions Date/heure | Les fonctions de dates et heures sont disponibles dans l'Editeur texte. |
| Ces opérateur sont disponibles dans l'éditeur arithmétique. | |
| Elles retournent des valeurs spécifiques aux entités. | |
| Les paramètres FME et spécifiques au traitement peuvent être utilisés. | |
| Créer et modifier un paramètre publié | Créer ses propres paramètres éditables. |
Options - Tables
Les Transformers avec des paramètres de style table possèdent des outils additionnels pour remplir et manipuler des valeurs.
|
Réordonner
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
|
|
Couper, Copier et Coller
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
Copier, copier et coller peuvent être utilisés au sein d'un Transformer ou entre Transfromers. |
|
Filtre
|
Commencez à taper une chaîne de caractères, et la matrice n'affichera que les lignes correspondant à ces caractères. Recherche dans toutes les colonnes. Cela n'affecte que l'affichage des attributs dans le Transformer - cela ne change pas les attributs qui sont sortis. |
|
Importer
|
Le bouton d'import remplit la table avec un jeu de nouveaux attributs lus depuis un jeu de données. L'application spécifique varie selon les Transformers. |
|
Réinitialiser/Rafraîchir
|
Réinitialise la table à son état initial, et peut fournir des options additionnelles pour supprimer des entrées invalides. Le comportement varie d'un Transformer à l'autre. |





Note : Tous les outils ne sont pas disponibles dans tous les Transformers.
FME Community
FME Community est l'endroit où trouver des démos, des tutoriaux, des articles, des FAQ et bien plus encore. Obtenez des réponses à vos questions, apprenez des autres utilisateurs et suggérez, votez et commentez de nouvelles entités.
Voir tous les résultats à propos de ce Transformer sur FME Community.
Mots clefs : aggregate aggregation "technology preview"