Exécute un script Python fourni par l'utilisateur pour manipuler les entités.
Cas d'utilisation courants
- Tâches ou un Transformer n'est pas disponible.
- Utilisation de modules externes pour le traitement.
- Réalisation de manipulations complexes sur des attributs de liste.
Comment fonctionne-t-il ?
PythonCaller exécute un script Python pour manipuler les entités.
Lorsqu'une tâche spécialisée est nécessaire telle qu'une analyse statistique personnalisée d'un attribut et que FME Workbench ne fournit pas de Transformer adapté, un script Python peut permettre de mener à bien de type d'opérations complexes sur les attributs, les géométries et les systèmes de coordonnées.
Accès fourni via l'API Python FME Objects.
L'utilisation de Python pour effectuer des opérations arbitraires sur des entités est un aspect puissant de FME Workbench. Cependant, la logique introduite dans un FME Workbench est moins visible et peut donc être plus difficile à maintenir que la logique construite à l'aide des Transformers intégrés de traitement. Il est recommandé d'utiliser d'autres Transformers lorsque cela est possible plutôt que des scripts Python.
Interface Classe
Le PythonCaller peut s'interfacer avec une classe définie dans un script Python. La séquence d'appel des méthodes définies dans une classe dépend du mode dans lequel se trouve le PythonCaller. Il existe deux modes - Standard et Regrouper par .
Mode standard
Il s'agit du mode de fonctionnement lorsqu'aucun attribut n'est défini dans le paramètre Regrouper par. Dans ce mode, qui est le plus courant, le PythonCaller aura la séquence d'appel suivante sur une classe :
- __init__() - appelée une fois, que les entités soient traitées ou non.
- input() - appelée pour chaque FMEFeature qui vient dans le port d'entrée.
- close() -- Appelée une fois, après le traitement de toutes les entités (lorsqu'il ne reste plus de FMEFeatures). Si aucune entité n'est traitée, la méthode close() sera quand même appelée.
Les entités qui doivent continuer dans le traitement pour de futurs traitements doivent être explicitement écrits en utilisant la méthode pyoutput().
Lorsque l'interface de classe traite les FMEFeatures entrants un par un, la méthode pyoutput() doit être appelée une fois par FMEFeature entrant dans la méthode input(). À l'inverse, lorsque l'interface de classe opère sur un groupe de FMEFeatures, les FMEFeatures entrants peuvent être stockés dans une liste, puis traités et écrits par la méthode pyoutput() dans la méthode close().
L'exemple ci dessous totalise la superficie des géométries de toutes les entités traitées puis génère toutes les entités avec un nouvel attribut contenant la superficie totale :
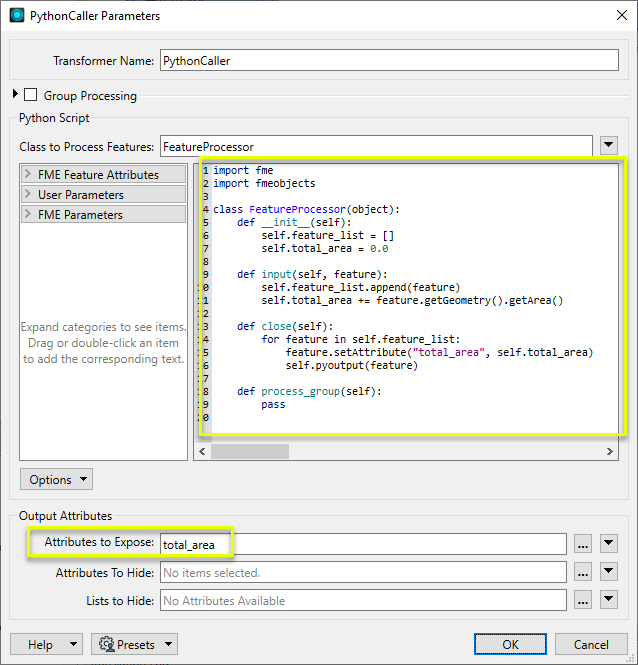
Traitement des regroupements
Il s'agit du mode de fonctionnement lorsqu'un ou plusieurs attributs sont définis dans le paramètre Regrouper par. Dans ce mode, le PythonCaller aura la séquence d'appel suivante sur une classe :
- __init__() - appelée une fois, que les entités soient traitées ou non.
- input() - appelée pour chaque entité dans un groupe.
- process_group() - Appelé après que toutes les FMEFeatures d'un groupe ont été envoyées à input(). Après l'appel et l'exécution de cette fonction, PythonCaller enverra le prochain groupe de FMEFeatures à input() et appellera ensuite à nouveau process_group(). Ceci est répété jusqu'à ce que tous les groupes aient été épuisés.
- close() - Appelée une fois, après que tous les tours de input() et de process_group() aient été appelés pour traiter toutes les entités entrantes (lorsqu'il ne reste plus de FMEFeatures). Si aucune entité n'est traitée, la méthode close() sera quand même appelée.
Dans ce mode, l'interface de la classe travaille sur des groupes de FMEFeatures. Les FMEFeatures entrants doivent être stockés dans une variable membre de la classe liste, puis traités et écrits à travers pyoutput() dans la méthode process_group(). Une fois le traitement terminé dans process_group(), toutes les variables membres de la classe doivent être effacées pour le prochain cycle de traitement des groupes. Au tour suivant, les caractéristiques FMEF du groupe suivant sont passées par des appels input() suivis à nouveau par process_group(). Ceci est répété jusqu'à ce que tous les groupes soient épuisés.
L'exemple ci dessous calcule la superficie totale des géométries de toutes les entités regroupée selon l'attribut _shape puis ressort toutes les entités avec un nouvel attribut contenant le total de surface de chaque groupe.
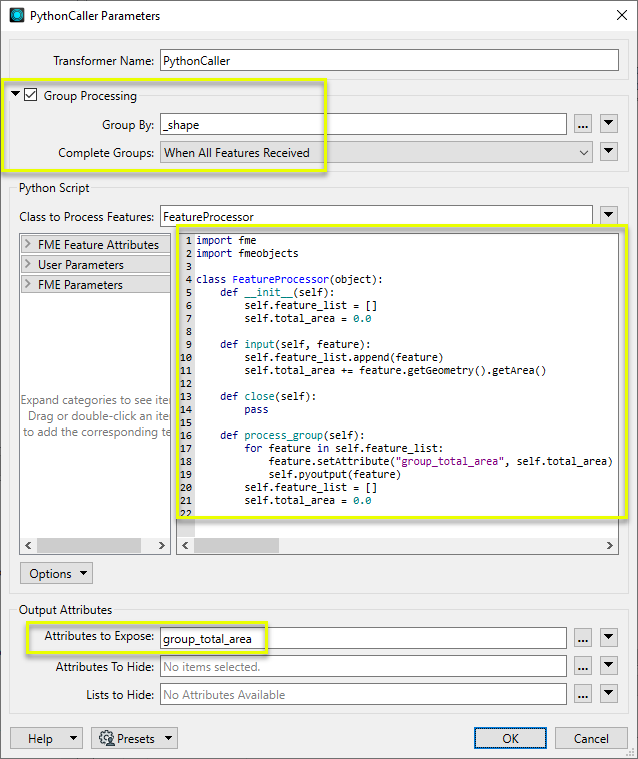
Edition de Script
PythonCaller peut appeler tous les scripts stockés dans le Transformer lui même ou les scripts stockés dans l'ensemble du traitement :
- Pour stocker un script Python avec un Transformer PythonCaller spécifique, utiliser le paramètre Script Python.
- Pour stocker un script Python de manière globale, cliquez sur le paramètre Traitement > Scriptage dans le navigateur, puis double-cliquez sur Script Python de lancement . Le stockage global des scripts présente l'avantage de centraliser la logique Python, ce qui facilite l'édition et la maintenance. Cela est utile lorsque plusieurs Transformers PythonCaller du traitement utilisent le même script. Pour plus d'informations, consultez la rubrique Lancement et arrêt de scripts Python dans l'aide de FME Workbench.
FME peut accéder aux modules .py qui sont stockés dans le système de fichiers, y compris les modules des bibliothèques Python externes. Utilisez la commande Python "import" pour charger ces modules. FME effectuera une recherche dans les emplacements standard des modules Python et dans l'emplacement dans le traitement pour trouver le module à importer.
Configuration
Ports en entrée
Entités à manipuler
Ports de sortie
Entités, incluant toute modification effectuée
Paramètres
|
Regrouper par |
Si le paramètre Regrouper par est défini, une entité par groupe est produite. |
||||
|
Traitement des regroupements |
Sélectionnez le moment du traitement où les groupes sont traités :
Il y a deux raisons typiques d'utiliser Quand le groupe change (avancé). La première concerne les données entrantes qui sont destinées à être traitées en groupes (et qui sont déjà classées ainsi). Dans ce cas, c'est la structure qui dicte l'utilisation de Regrouper par - et non des considérations de performance. La seconde raison possible est le potentiel gain de performances. Les gains de performance sont plus visibles quand les données sont déjà triées (ou lues en utilisant une déclaration SQL ORDER BY) puisque moins de travail est requis de la part de FME. Si les données doivent être ordonnées, elles peuvent être triées dans le traitement (bien que la surcharge de traitement supplémentaire puisse annuler tout gain). Le tri devient plus difficile en fonction du nombre de flux de données. Il peut être quasiment impossible de trier des flux de données multiples dans l'ordre correct, car toutes les entités correspondant à une valeur Regrouper par doivent arriver avant toute entité (de tout type d'entité ou jeu de données) appartenant au groupe suivant. Dans ce cas, l'utilisation de Regrouper par avec Lorsque toutes les entités sont reçues peut être une approche équivalente et plus simple. Note De multiples types d'entités et entités de multiples jeux de données ne vont généralement pas arriver dans l'ordre correct.
Comme pour beaucoup de scénarios, tester différentes approches dans votre traitement avec vos données est le seul moyen sûr d'identifier le gain de performance. |
|
Classe pour traiter les entités |
Le nom de la classe Python dans le script que PythonCaller utilisera pour commencer l'exécution. Pour les exemples ci-dessus, définissez ce paramètre sur FeatureProcessor. |
|
Script Python |
Le script Python à exécuter. Lorsque le script Python est stocké en tant que script Python de démarrage de le traitement, laissez ce paramètre vide. |
|
Attributs à exposer : |
Expose les attributs afin qu'ils puissent être utilisés ailleurs dans le traitement. Les noms des attributs peuvent être saisis directement ou fournis dans la fenêtre Entrer des valeurs pour les attributs à exposer, à laquelle on accède par le bouton "...", où le type de données peut également être spécifié. Pour plus d'informations sur les attributs exposés et non exposés, voir Comprendre les types d'entités et les attributs. Utilisé pour exposer les attributs créés par le script Python exécuté afin qu'ils puissent être utilisés par d'autres Transformers. |
|
Attributs à masquer |
Cache tous les attributs qui peuvent être supprimés par le script Python en cours d'exécution. Les autres Transformers ne seront pas en mesure d'utiliser ces attributs. |
|
Listes à masquer |
Cache toutes les listes qui peuvent être supprimées par l'expression Python en cours d'exécution. Les autres Transformers ne seront pas en mesure d'utiliser ces listes. Notez que si vous choisissez de masquer une liste, votre sélection comprendra tous les attributs de liste ou les listes imbriquées. Par exemple, si vous choisissez de masquer une liste appelée list{} alors list{}.attr ou list{}.sublist{} seront aussi masqués. |
Éditer les paramètres des Transformers
À l'aide d'un ensemble d'options de menu, les paramètres du Transformer peuvent être attribués en faisant référence à d'autres éléments de traitement. Des fonctions plus avancées, telles qu'un éditeur avancé et un éditeur arithmétique, sont également disponibles dans certains Transformers. Pour accéder à un menu de ces options, cliquez sur  à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
Définir les valeurs
Il existe plusieurs façons de définir une valeur à utiliser dans un Transformer. La plus simple est de simplement taper une valeur ou une chaîne de caractères, qui peut inclure des fonctions de différents types comme des références d'attributs, des fonctions mathématiques et de chaînes de caractères, et des paramètres de traitement. Il existe un certain nombre d'outils et de raccourcis qui peuvent aider à construire des valeurs, généralement disponibles dans le menu contextuel déroulant adjacent au champ de valeur.
Utilisation de l'éditeur de texte
L'éditeur de texte fournit un moyen efficace de construire des chaînes de textes (dont les expressions régulières) à partir de données source diverses, telles que des attributs, des paramètres et des constantes, et le résultat est directement utilisé dans le paramètre.
Utilisation de l'éditeur arithmétique
L'éditeur arithmétique fournit un moyen simple de construire des expressions mathématiques à partir de plusieurs données source, telles que des attributs et des fonctions, et le résultat est directement utilisé dans un paramètre.
Valeur conditionnelle
Définit des valeurs selon un ou plusieurs tests.
Fenêtre de définition de conditions
Contenu
Les expressions et chaînes de caractères peuvent inclure des fonctions, caractères, paramètres et plus.
Lors du paramétrage des valeurs - qu'elles soient entrées directement dans un paramètre ou construites en utilisant l'un des éditeurs - les chaînes de caractères et les expressions contenant des fonctions Chaîne de caractères, Math, Date et heure ou Entité FME auront ces fonctions évaluées. Par conséquent, les noms de ces fonctions (sous la forme @<nom_de_fonction>) ne doivent pas être utilisés comme valeurs littérales de chaîne de caractères.
| Ces fonctions manipulent les chaînes de caractères. | |
|
Caractères spéciaux |
Un ensemble de caractères de contrôle est disponible dans l'éditeur de texte. |
| Plusieurs fonctions sont disponibles dans les deux éditeurs. | |
| Fonctions Date/heure | Les fonctions de dates et heures sont disponibles dans l'Editeur texte. |
| Ces opérateur sont disponibles dans l'éditeur arithmétique. | |
| Elles retournent des valeurs spécifiques aux entités. | |
| Les paramètres FME et spécifiques au traitement peuvent être utilisés. | |
| Créer et modifier un paramètre publié | Créer ses propres paramètres éditables. |
Options - Tables
Les Transformers avec des paramètres de style table possèdent des outils additionnels pour remplir et manipuler des valeurs.
|
Réordonner
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
|
|
Couper, Copier et Coller
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
Copier, copier et coller peuvent être utilisés au sein d'un Transformer ou entre Transfromers. |
|
Filtre
|
Commencez à taper une chaîne de caractères, et la matrice n'affichera que les lignes correspondant à ces caractères. Recherche dans toutes les colonnes. Cela n'affecte que l'affichage des attributs dans le Transformer - cela ne change pas les attributs qui sont sortis. |
|
Importer
|
Le bouton d'import remplit la table avec un jeu de nouveaux attributs lus depuis un jeu de données. L'application spécifique varie selon les Transformers. |
|
Réinitialiser/Rafraîchir
|
Réinitialise la table à son état initial, et peut fournir des options additionnelles pour supprimer des entrées invalides. Le comportement varie d'un Transformer à l'autre. |





Note : Tous les outils ne sont pas disponibles dans tous les Transformers.
Références
|
Comportement |
Basé sur les entités ou Basé sur les groupes, conditionnel sur le script Python. |
|
Stockage des entités |
Conditionnel sur le script Python. |
| Dépendances |
Une installation de FME comprend un interpréteur Python version 2.7 et Python version 3.5. L'interpréteur Python par défaut utilisé pour le traitement Python est l'interpréteur Python 2.7. L'API Python de FME Objects prend en charge Python 2.7, Python 3.4 et Python 3.5. L'interpréteur Python utilisé par FME pour exécuter des scripts Python est contrôlé par le paramètre de traitement Compatibilité Python et le paramètre Interpréteur Python préféré dans le menu Outils > Options FME > Traitement. Compatibilité Python spécifie la version de Python avec laquelle les scripts Python sont compatibles. FME charge l'interpréteur Python préféré s'il est compatible avec la Compatibilité Python. Sinon, FME charge un interpréteur Python approprié correspondant à la Compatibilité Python. Pour plus d'informations, voir l'aide de FME Workbench. Consulter la section Installer le package Python pour FME dans l'aide de FME Workbench. |
| Alias | |
| Historique |
FME Community
FME Community est l'endroit où trouver des démos, des tutoriaux, des articles, des FAQ et bien plus encore. Obtenez des réponses à vos questions, apprenez des autres utilisateurs et suggérez, votez et commentez de nouvelles entités.
Voir tous les résultats à propos de ce Transformer sur FME Community.
Les exemples peuvent contenir des informations sous licence Open Government - Vancouver et/ou Open Government - Canada.