La répartition par jeu de données écrit un jeu de données différent pour chaque répartition de données. La manière dont cela apparaît réellement en sortie dépend du format.
Pour une introduction sur la répartition de jeux de données et de types d'entités , consulter la section A propos de la répartition.
Étapes
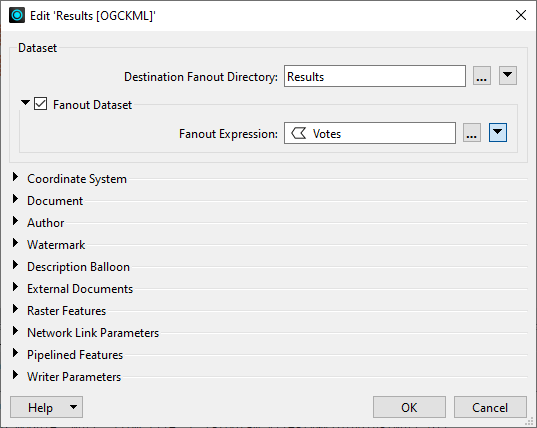
- Dans le Navigateur du Traitement, double cliquer sur le jeu de données destination du Writer que pour lequel vous souhaitez faire une répartition.
- Dans le champ Répertoire destination de répartition, préciser un répertoire pouvant contenir les jeux de données de répartition.
- Cocher Jeu de données de répartition et fournir une Expression de répartition pour indiquer comment vous souhaitez répartir le jeu de données.
- Cliquez sur OK.
Une fenêtre Editer le jeu de données s'ouvre.
Cliquer sur l'ellipse  pour utiliser l'Editeur de texte afin d'assembler une expression de constantes, paramètres, et attributs de sortie.
pour utiliser l'Editeur de texte afin d'assembler une expression de constantes, paramètres, et attributs de sortie.
Pour les Jeux de données basés sur des fichiers, l'expression doit correspondre au nom de fichier entier des fichiers en sortie, y compris les préfixes et extensions de fichiers (par exemple, internal\KML\@Value(PathName).gml ou @Value(PathName).dwg).
Par exemple, vous souhaitez effectuer une répartition d'un jeyu de données au format Google KML, et trois entités sont produites : deux ont un attribut Votes égal à candidate, et une a un attribut Votes égal à write_in. Si le répertoire de répartition de destination est C:\ et que l'expression de répartition est Votes (ou @Value(Votes) dans l'éditeur de texte), vous obtiendrez des jeux de données dans deux dossiers : c:\candidate\ et c:\cwrite_in\. Les noms des fichiers Shapefile de sortie seront basés sur les types d'entités de sortie spécifiés dans le traitement.
Note Si les valeurs d'attributs sont les mêmes mais les noms de fichiers n'ont pas la même casse (majuscule/minuscule) alors dans un environnement Windows, le fichier créé sera écrasé.
Par exemple, supposons qu'il y ait deux noms de fichier de source d'entrée et que la seule différence entre eux soit que l'un est en minuscules (3s1w35.dgn) et l'autre en majuscules (3S1W35.dgn). Avec la répartition de jeux de données, vous obtiendrez deux valeurs uniques. Comme FME crée deux Writers différents au cours de l'exécution, le second écrase le fichier créé par le premier. En effet, sous Windows, les noms de fichiers préservent la casse, mais sont également insensibles à la casse pour diverses opérations. Pour éviter cela, ajoutez un Transformer StringCaseChanger à la pour vous assurer que les noms d'attributs sont cohérents.traitement
Combiner la répartition de types d'entités et de jeux de données
Vous pouvez combiner les répartitions des types d'entités et des jeux de données.
Par exemple, si vous travaillez avec un format basé sur des dossiers et que vous effectuez une répartition des types d'entités selon l'attribut A et une répartition de jeux de données selon l'attribut B, vous générerez plusieurs dossiers et fichiers avec les noms de fichiers dépendant de l'attribut A.
Répartition de jeu de données et stockage temporaire
Notez qu'une répartition de jeux de données peut avoir un impact énorme sur le stockage temporaire sur disque, car il n'y a aucune garantie que les entités arrivent à l'éventail dans un seul groupe de jeux de données. Par conséquent, FME doit écrire tous les jeux de données dans le stockage temporaire et les répartir ensuite.
En couplant la répartition par jeux de données et par types d'entités, la quantité d'éléments stockés temporairement varie selon le type de format de destination (fichier ou répertoire).