Une répartition est un moyen dans FME de diviser les données de sortie en fonction de la valeur d'un attribut. Les données sont divisées au moment de l'écriture, plutôt que dans le traitement lui-même.
Il existe deux types de répartition : la répartition de type entités et la répartition de jeu de données. Vous pouvez définir à la fois une répartition de type d'entités ET une répartition de jeu de données dans le même traitement. La répartition de jeu de données produit un certain nombre de jeux de données de sortie, chacun d'entre eux comportant un certain nombre de couches créées par la répartition de type d'entités.
On peut Répartir un jeu de données depuis le navigateur et on peut répartir les types d'entités depuis la fenêtre du types d'entiés destination.
Répartition de jeux de données
Un jeu de données de répartition divise les données et écrit un jeu de données différent pour chaque division. Dans cet exemple, les données sont divisées en un certain nombre de jeux de données sur la base d'un attribut d'élévation.
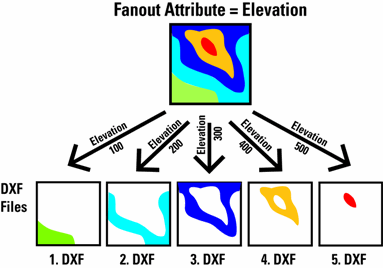
Répartition de type d'entités
Un éventail de types d'entités écrit un seul jeu de données mais divise les données en un certain nombre de couches/thèmes/types d'entités/objets/classes dans ce jeu de données. Dans cet exemple, les données sont divisées en un certain nombre de couches sur la base d'un attribut d'élévation.
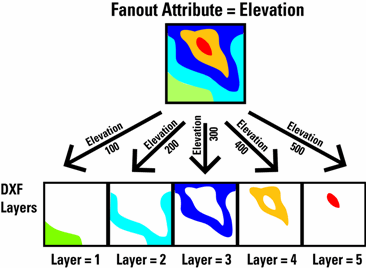
Exemples
La différence entre la répartition d'un jeu de données et la répartition de type d'entités est plus facilement explicable au travers d'exemples :
Données :
- Un jeu de données de type points (par exemple des arbres dans une ville)
- Un jeu de données de type polygone (par exemple arrondissement d'une ville)
Le but est de générer un fichier de points DXF regroupés en couches par arrondissement.
Les polygones ont un attribut contenant le code du quartier. Après avoir effectué un simple PointOnAreaOverlayer, cet attribut a été transféré aux points. Sur le type d'entité de sortie, nous avons défini la répartition en fonction de cet attribut. Cela va regrouper les points par quartier et créer une couche séparée pour chaque groupe. Il s'agit d'une répartition de type d'entité.
Un deuxième défi consiste à produire un fichier DXF par quartier. Après avoir désactivé la répartition du type d'entité, nous passons au jeu de données (dans le panneau de traitement) et utilisons à nouveau l'attribut de voisinage. Cela génère alors un fichier DXF distinct par quartier. Il s'agit d'une répartition de jeu de données.
Fichier et dossier de jeu de données
Le comportement d'un regroupement change selon si l'on travaille avec un format basé sur un fichier ou un format basé sur un dossier.
Par exemple :
- Un Writer DWG (basé sur un fichier) crée de nouvelles couches avec une répartition par type d'entités et de nouveaux dessins avec une répartition par jeu de données.
- Un Writer Microsoft Excel XLSXW2 (également basé sur un fichier) crée de nouveaux onglets avec une répartition par type d'entités, et de nouveaux fichiers .xls avec une répartition par jeu de données.
- Un writer Esri Shapefile (basé sur un dossier) crée de nouveaux fichiers shape avec une répartition par type d'entités et de nouveaux fichiers .xls avec une répartition par jeux de données.
Chaque format dans le manuel FME Readers and Writers contient un tableau spécifiant les formats des jeux de données.
Regroupement multi-attributaire
Chaque paramètre de répartition ne permet à l'utilisateur de sélectionner qu'un seul attribut pour la répartition. Toutefois, il est possible de créer des répartitions multi-attributs en fusionnant des attributs à l'aide du Transformer StringConcatenator.