Utilisations typiques
- Transférer les valeurs de composants entre co-nuages de points
- Opérer des détection de changements entre nuages de points
- Supprimer des points dupliqués entre nuages de points.
Comment fonctionne-t-il ?
PointCloudMerger reçoit des nuages de points et les fusionne en identifiant les points correspondants selon la valeur d'un composant qui peut inclure le (x, y, et z ) et autres composants standards et utilisateurs.
Il y a deux ports d'entrée :
- Requestor : Nuages de points qui reçoivent les valeurs des composant fusionnées.
- Supplier: Nuages de points qui fournissent les valeurs de composants.
Les pointsRequestor et Supplier sont correspondants quand les composants spécifiés dans le paramètre de jointure ont tous la même valeur.
Plusieurs nuages de points peuvent être envoyés à l'un ou l'autre des ports, et ils peuvent être groupés. Le même nuage de points peut être connecté aux deux ports d'entrée.
Il y a plusieurs ports de sortie, chacun produit un nuage de points avec les caractéristiques suivantes :
- Merged: les points du Requestor qui ont trouvé une correspondance et qui reçoivent des valeurs des composants d'un Supplier.
Quand des points Supplier dupliqués sont trouvés, seul le premier rencontré est utilisé, et les points Requestor ne sont pas dupliqués. - Not Merged: Les points du Requestor n'ayant pas trouvé de correspondance dans le Supplier.
À des fins de détection des changements (lorsque le demandeur est le nuage de points d'origine), ces derniers peuvent avoir été supprimés ou la valeur d'un composant peut avoir été modifiée. - Referenced: Les points fournisseurs (Supplier) trouvés par au moins un demandeur ressortent par ce port et leurs valeurs de composants sont transférées aux points demandeurs.
- Unreferenced: Les points fournisseurs trouvés par aucun demandeur ressortent par ce port.
À des fins de détection des changements (lorsque le demandeur est le nuage de points d'origine), ces derniers peuvent avoir été supprimés ou la valeur d'un composant peut avoir été modifiée. - Duplicate Supplier: Les points fournisseurs avec le même composant de jointure qu'un autre fournisseur ressortent par ce port.
Lorsqu'un demandeur trouve un fournisseur, les composants de ce dernier sont fusionnés sur le demandeur. Si le demandeur disposait déjà d'un composant portant le même nom, le paramètre de Résolution de conflits détermine quelle valeur est préférée pour le nuage de points fusionné.
Exemples
Dans cet exemple, nous disposons de deux nuages de points co situés, chacun ayant des ensembles de composants différents.
Le premier a une sélection de composants standards mais n'a pas de classification.
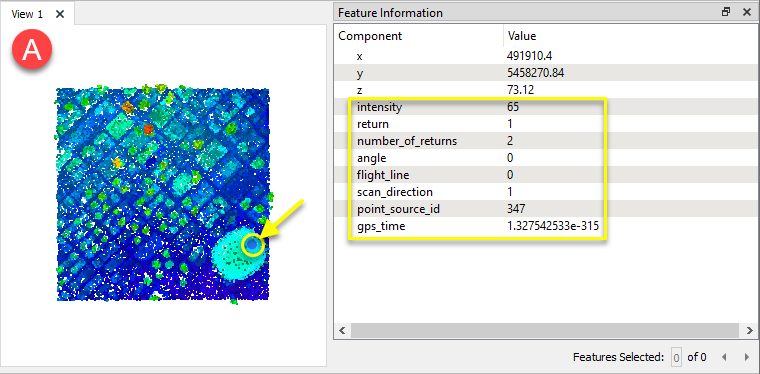
Le second a un composant classification .
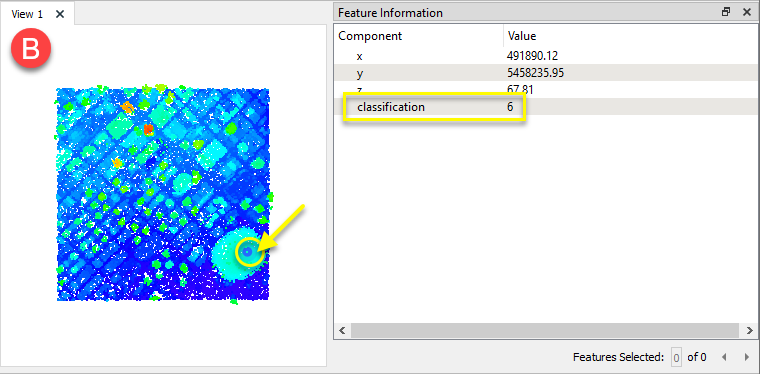
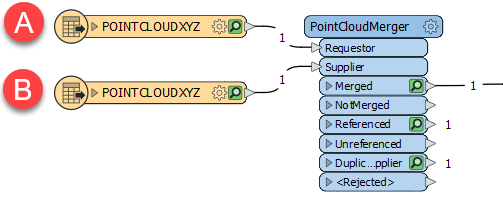
Les deux nuages de points sont acheminés dans un PointCloudMerger. Le premier (A) est le demandeur, et le second (B) est le fournisseur. Tous les composants sur B seront fusionnés sur A.
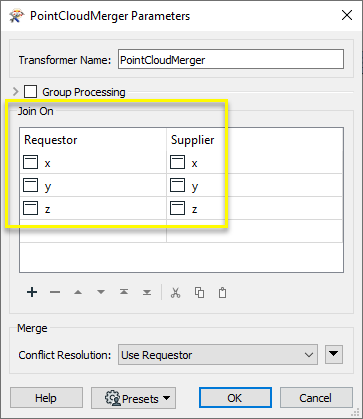
Dans le fenêtre de paramétrage, une jointure est définie pour les composants x, y, et z pour faire correspondre les points selon leur position.
Le nuage de points en sortie du port Merged contient tous les points ayant trouvé une correspondance de position et contient les composants des deux nuages de points.
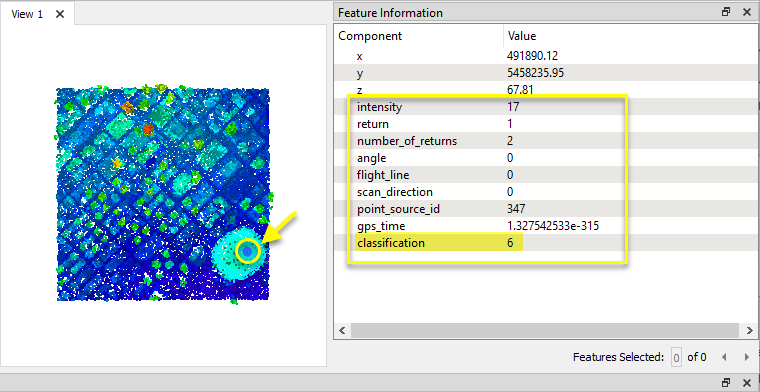
Dans cet exemple, nous avons deux nuages de points, dont l'un est une version amincie de l'autre. Nous voulons identifier les points qui ont été supprimés lors du processus d'éclaircissement.
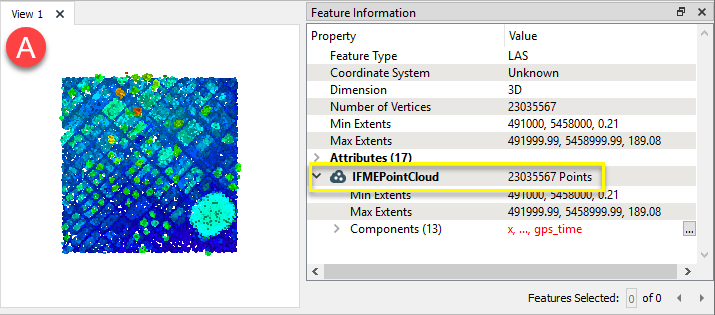
Le nuage initial (A) a 23,035,567 points.
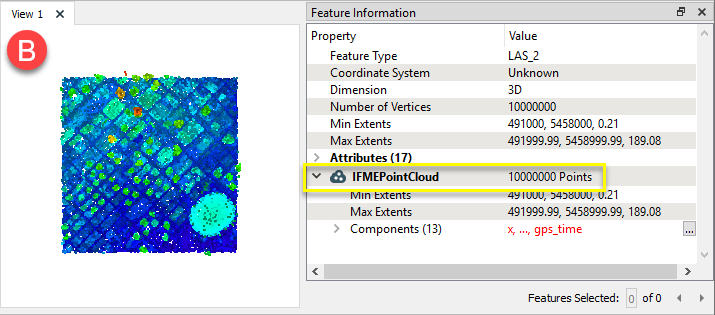
Le nuage de point réduit (B) a 10,000,000 points.
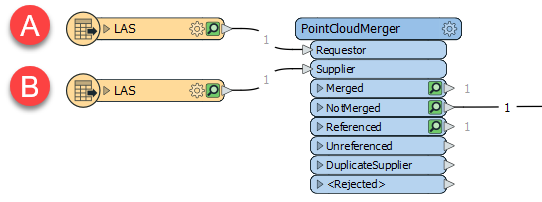
Les deux nuages de points sont acheminés dans un PointCloudMerger. L'original (A) est le demandeur, et le nuage de points affiné (B) est le fournisseur.
Dans le fenêtre de paramétrage, une jointure est définie pour les composants x, y, et z pour faire correspondre les points selon leur position.
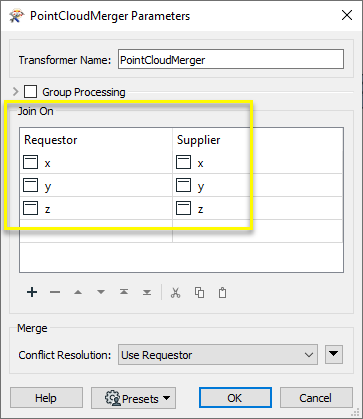
Le nuage de points en sortie du port Merged contient les points qui existent dans les deux nuages (origine et réduit).
Le nuage de points en sortie du port NotMerged contains 13,035,567 points contenus dans le nuage d'origine et qui ne le sont pas dans le nuage réduit - donc supprimés.
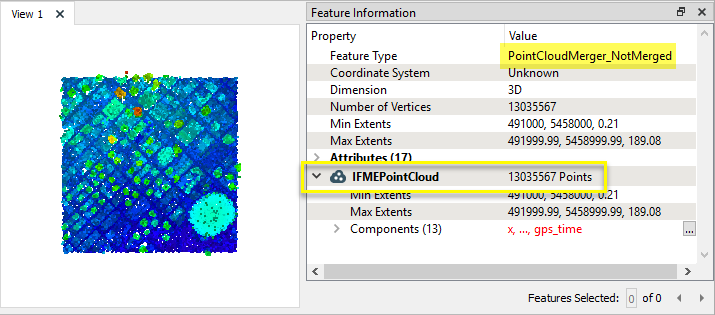
Dans cet exemple, nous avons un nuage de points XYZ de 10 000 000 de points. Le fichier fait plus de 600 Mo, et nous voulons en réduire la complexité.
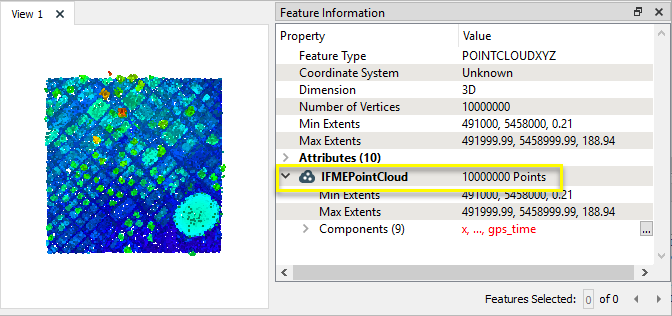
Les coordonnées sont de type FLOAT.
Deux étapes sont nécessaires :
- Arrondi des coordonnées en les convertissant en entier via PointCloudComponentTypeCoercer.
- Identification et suppression des doublons avec PointCloudMerger.
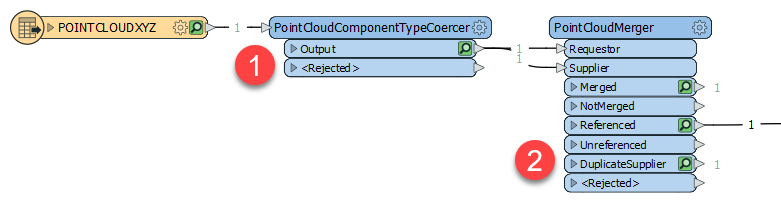
Dans la fenêtre de paramétrage du PointCloudComponentTypeCoercer, les composants x, y, et z sont convertis en Int32 (32-bit integer), et arrondis.
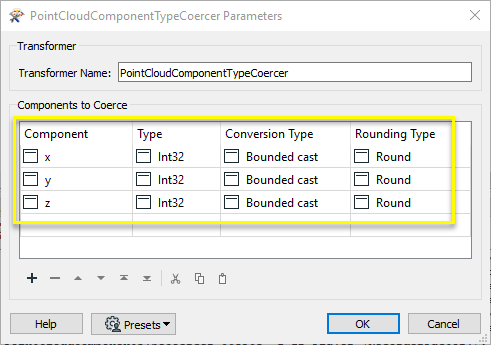
Les coordonnées sont desormais des entiers.
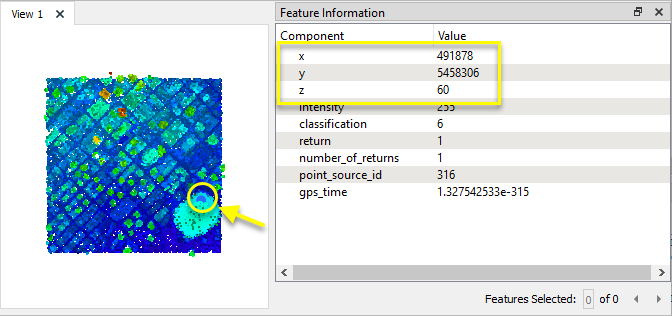
Le nuage de points est connecté au PointCloudMerger vers les deux ports d'entrée Supplier et Requestor - et est de la sorte fusionner à lui même.
L'arrondi des coordonnées a produit un grand nombre de positions de points dupliquées. Dans le cas où un emplacement contient plusieurs points avec des valeurs de classification différentes, nous voulons conserver un point de chaque classification.
Une jointure est opérée sur les composants x, y, etz et la classification est jointe.
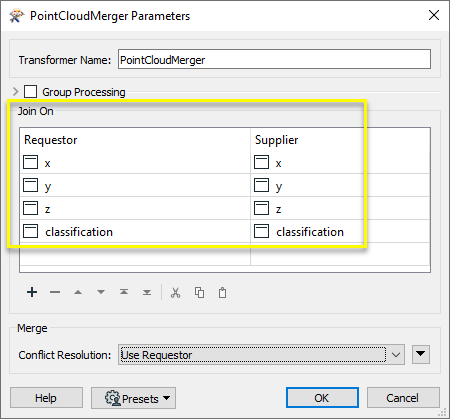
Lorsqu'une fusion est effectuée, chaque point unique de Supplier (fournisseurs dont l'unicité est déterminée par la combinaison de toutes les valeurs de composant Jointure définies) est utilisé une seule fois. La première instance est produite dans le nuage de points référencé, et tous les doublons sont produits dans le nuage de points DuplicateSupplier.
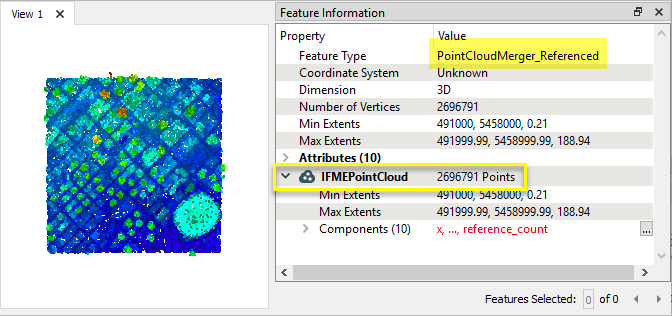
En fusionnant le nuage de point avec une copie de lui même, tous les points uniques Referenced ressortent qu'une seule fois, en éliminant efficacement les doublons du nuage.
Notez que le nuage de points Referenced a 2,696,791 points
Notes
- Pour concaténer ou combiner des nuages de points entre eux, utiliser PointCloudCombiner.
- Un seul nuage de points peut être connecté aux deux ports d'entrée, ce qui permet d'identifier et de supprimer les points en double.
- Lors de la fusion basée sur les composantes x, y et z, les valeurs doivent correspondre exactement. Un PointCloudExpressionEvaluator peut être utilisé pour arrondir les valeurs et assurer la correspondance.
Choisir un Transformer Nuages de points
FME possède une gamme de Transformers spécialisés dans le traitement de données nuages de points.
Pour plus d'informations sur les propriétés et géométrie des nuages de points, vois Nuages de points (IFMEPointCloud).
|
Combine les entités en un seul nuage de points. Les géométries de nuages de points et de nuages non ponctuels sont prises en charge. |
|
|
Ajoute de nouveaux composants de valeurs constantes à un nuage de points. |
|
|
Copie les valeurs des composants sélectionnés dans des composants soit nouveaux soit existants. |
|
|
Conserve seulement les composants nuages de points spécifiés, supprimant tous les autres. |
|
|
Supprime les composants spécifiés d'un nuage de points. |
|
|
Renomme un composant existant. |
|
|
Modifie le type de données de composants nuages de points et convertit les valeurs des composants si besoin est. |
|
|
Lit les entités du nuage de points à des fins de test, y compris toute opération accumulée sur le nuage de points. Aucune opération supplémentaire n'est effectuée, et rien n'est fait avec les entités. |
|
|
Crée un nuage de points selon une taille et une densité avec des valeurs de composants par défaut |
|
|
Calcule des expressions sur chaque point dans une entité nuage de points, comme des opérations algébriques et des déclarations conditionnelles, et définit les valeurs de chaque composant nuage de points. |
|
|
Sérialise la géométrie d'une entité raster dans un attribut Blob, encodant le contenu selon un choix de formats nuages de points binaires classiques. |
|
|
Sépare les nuages de points en plusieurs entités, en se basant sur l'évaluation d'expressions comprenant des valeurs de composants, et crée un port de sortie distinct pour chaque expression définie. |
|
|
Fusionne les nuages de points en joignant les points où les valeurs des composants sélectionnés correspondent (clé de jonction), y compris les composants x, y, z et autres. Les valeurs des composantes sont transférées entre les nuages de points et la sortie est filtrée en fonction de la réussite de la correspondance et de la duplication. |
|
|
Définit les valeurs des composantes du nuage de points en superposant un nuage de points sur une trame. Les valeurs des composantes de chaque point sont interpolées à partir des valeurs de la bande à l'emplacement du point. |
|
|
Extrait les propriétés géométriques d'une entité de nuage de points et les expose en tant qu'attributs, en vérifiant éventuellement leur existence, en récupérant les propriétés des composants et en trouvant les valeurs minimales et maximales. Les étendues peuvent également être recalculées et mises à jour. |
|
|
Décode un attribut binaire contenant des nuage de points encodés stockés en tant que blobs, puis remplace la géométrie de l’entité avec le nuage de point décodé. |
|
|
Réduit le nombre de points dans un nuage de points en conservant sélectivement les points en fonction de la forme du nuage de points. Les points simplifiés et supprimés sont produits comme deux nuages de points discrets. |
|
|
Tri les points d'un nuage de points en fonction des valeurs de ses composants |
|
|
Découpe un nuage de points en plusieurs entités, chacune ayant des valeurs homogènes pour les composants ayant servi de critère de découpage. |
|
|
Calcule des statistiques sur les composants des nuages de points et ajoute les résultats sous la forme d'attributs. |
|
|
Prend un nuage de points en entrée et le reconstruit dans une maille. |
|
|
Réduit le nombre de points dans (amincit) un nuage de points en conservant les points à un intervalle fixe, un nombre maximum de points, ou une quantité définie de premiers ou de derniers points. Les points restants sont éliminés. |
|
|
Convertit des nuages de points en points ou géométries multi-points, retenant optionnellement des valeurs d'attributs et composants. |
|
|
Applique une échelle, un décalage ou une transformation matricielle pour recalculer des valeurs de composants et supprimer des valeurs de transformation |
Configuration
Ports en entrée
Les nuages de points à fusionner et devant recevoir les composants des Suppliers.
Les nuages de points devant fournir leurs valeurs de composants aux Requestors.
Ports de sortie
Les points Requestor ayant trouvé une correspondance avec les Suppliers, avec les valeurs de composants transférées
Les demandeurs qui ne trouvent pas de fournisseur ressortent par ce port.
Les points fournisseurs trouvés par au moins un demandeur ressortent par ce port.
Les nuages de points ressortent via ce port avec un composant supplémentaire reference_count, spécifiant le nombre de fois où chaque point a été référencé.
Les points fournisseurs trouvés par aucun Demandeur.
Les points fournisseurs avec le même composant de Jointure qu'un précédent fournisseur ressortent par ce port.
Les entités non nuages de points sont dirigées vers le port <Rejected>, de même que les nuages de points invalides.
Les entités rejetés auront un attribut fme_rejection_code avec l'une des valeurs suivantes :
INVALID_GEOMETRY_TYPE
Gestion des entités rejetées : ce paramètre permet d'interrompre la traduction ou de la poursuivre lorsqu'elle rencontre une entité rejetée. Ce paramètre est disponible à la fois comme option par défaut de FME et comme paramètre de traitement.
Paramètres
|
Regrouper par |
Si des attributs de regroupement sont sélectionnés, les entités avec les mêmes valeurs pour les attributs de regroupement seront regroupées et les nuages de points seront utilisés uniquement pour définir les valeurs des composants des nuages de points du même groupe. |
|
Traitement des regroupements |
Lorsque toutes les entités sont reçues : comportement par défaut. Le traitement n'aura lieu qu'une fois que toutes les entités en entrée seront présente. Quand le groupe change (avancé) : ce Transformer traitera les groupes en entrée dans l'ordre. Les changements de la valeur du paramètre Regrouper par sur le flux d'entrée déclencheront le traitement du groupe en cours de regroupement. Cela peut améliorer la vitesse globale (en particulier avec plusieurs groupes de taille égale), mais peut provoquer un comportement indésirable si les groupes en entrée ne sont pas ordonnés. Il y a deux raisons typiques d'utiliser Quand le groupe change (avancé). La première concerne les données entrantes qui sont destinées à être traitées en groupes (et qui sont déjà classées ainsi). Dans ce cas, c'est la structure qui dicte l'utilisation de Regrouper par - et non des considérations de performance. La seconde raison possible est le potentiel gain de performances. Les gains de performance sont plus visibles quand les données sont déjà triées (ou lues en utilisant une déclaration SQL ORDER BY) puisque moins de travail est requis de la part de FME. Si les données doivent être ordonnées, elles peuvent être triées dans le traitement (bien que la surcharge de traitement supplémentaire puisse annuler tout gain). Le tri devient plus difficile en fonction du nombre de flux de données. Il peut être quasiment impossible de trier des flux de données multiples dans l'ordre correct, car toutes les entités correspondant à une valeur Regrouper par doivent arriver avant toute entité (de tout type d'entité ou jeu de données) appartenant au groupe suivant. Dans ce cas, l'utilisation de Regrouper par avec Lorsque toutes les entités sont reçues peut être une approche équivalente et plus simple. Note: De multiples types d'entités et entités de multiples jeux de données ne vont généralement pas arriver dans l'ordre correct. Comme pour beaucoup de scénarios, tester différentes approches dans votre projet avec vos données est le seul moyen sûr d'identifier le gain de performance. |
Chaque ligne de ce tableau spécifie une paire de jointures de composants. Plusieurs paires peuvent être définies, y compris des coordonnées et d'autres composants standard ou définis par l'utilisateur.
Les points sont considérés comme correspondants si les valeurs de tous les composants de la table sont correspondent.
|
Requestor |
Composants du Requestor à joindre. |
|
Supplier |
Composants du Supplier à joindre. |
Notez que les menus déroulants pour le demandeur et le fournisseur fournissent une liste de noms de composants standard. Les noms de composants spécifiés par l'utilisateur peuvent être saisis directement dans les deux colonnes.
|
Résolution de conflit |
Des conflits apparaissent lorsque les Demandeurs et Fournisseurs ont un composant avec le même nom.
|
Éditer les paramètres des Transformers
À l'aide d'un ensemble d'options de menu, les paramètres du Transformer peuvent être attribués en faisant référence à d'autres éléments du traitement. Des fonctions plus avancées, telles qu'un éditeur avancé et un éditeur arithmétique, sont également disponibles dans certains Transformers. Pour accéder à un menu de ces options, cliquez sur  à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
à côté du paramètre applicable. Pour plus d'informations, voir Options de menus et paramètres de Transformer.
Définir les valeurs
Il existe plusieurs façons de définir une valeur à utiliser dans un Transformer. La plus simple est de simplement taper une valeur ou une chaîne de caractères, qui peut inclure des fonctions de différents types comme des références d'attributs, des fonctions mathématiques et de chaînes de caractères, et des paramètres d'espace de travail. Il existe un certain nombre d'outils et de raccourcis qui peuvent aider à construire des valeurs, généralement disponibles dans le menu contextuel déroulant adjacent au champ de valeur.
Utilisation de l'éditeur de texte
L'éditeur de texte fournit un moyen efficace de construire des chaînes de textes (dont les expressions régulières) à partir de données source diverses, telles que des attributs, des paramètres et des constantes, et le résultat est directement utilisé dans le paramètre.
Utilisation de l'éditeur arithmétique
L'éditeur arithmétique fournit un moyen simple de construire des expressions mathématiques à partir de plusieurs données source, telles que des attributs et des fonctions, et le résultat est directement utilisé dans un paramètre.
Valeur conditionnelle
Définit des valeurs selon un ou plusieurs tests.
Fenêtre de définition de conditions
Contenu
Les expressions et chaînes de caractères peuvent inclure des fonctions, caractères, paramètres et plus.
Lors du paramétrage des valeurs - qu'elles soient entrées directement dans un paramètre ou construites en utilisant l'un des éditeurs - les chaînes de caractères et les expressions contenant des fonctions Chaîne de caractères, Math, Date et heure ou Entité FME auront ces fonctions évaluées. Par conséquent, les noms de ces fonctions (sous la forme @<nom_de_fonction>) ne doivent pas être utilisés comme valeurs littérales de chaîne de caractères.
| Ces fonctions manipulent les chaînes de caractères. | |
|
Caractères spéciaux |
Un ensemble de caractères de contrôle est disponible dans l'éditeur de texte. |
| Plusieurs fonctions sont disponibles dans les deux éditeurs. | |
| Fonctions Date/heure | Les fonctions de dates et heures sont disponibles dans l'Editeur texte. |
| Ces opérateur sont disponibles dans l'éditeur arithmétique. | |
| Elles retournent des valeurs spécifiques aux entités. | |
| Les paramètres FME et spécifiques au projet peuvent être utilisés. | |
| Créer et modifier un paramètre publié | Créer ses propres paramètres éditables. |
Options - Tables
Les Transformers avec des paramètres de style table possèdent des outils additionnels pour remplir et manipuler des valeurs.
|
Réordonner
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
|
|
Couper, Copier et Coller
|
Activé une fois que vous avez cliqué sur un élément de ligne. Les choix comprennent :
Copier, copier et coller peuvent être utilisés au sein d'un Transformer ou entre Transfromers. |
|
Filtre
|
Commencez à taper une chaîne de caractères, et la matrice n'affichera que les lignes correspondant à ces caractères. Recherche dans toutes les colonnes. Cela n'affecte que l'affichage des attributs dans le Transformer - cela ne change pas les attributs qui sont sortis. |
|
Importer
|
Le bouton d'import remplit la table avec un jeu de nouveaux attributs lus depuis un jeu de données. L'application spécifique varie selon les Transformers. |
|
Réinitialiser/Rafraîchir
|
Réinitialise la table à son état initial, et peut fournir des options additionnelles pour supprimer des entrées invalides. Le comportement varie d'un Transformer à l'autre. |





Note : Tous les outils ne sont pas disponibles dans tous les Transformers.
Références
|
Comportement |
|
|
Stockage des entités |
Oui |
| Dépendances | Aucun |
| Alias | |
| Historique |
FME Community
FME Community iest l'endroit où trouver des démos, des tutoriaux, des articles, des FAQ et bien plus encore. Obtenez des réponses à vos questions, apprenez des autres utilisateurs et suggérez, votez et commentez de nouvelles entités.
Rechercher tous les résultats sur ce Transformer sur FME Community.
Les exemples peuvent contenir des informations sous licence Open Government - Vancouver et/ou Open Government - Canada.
Mots clefs : points, nuage, nuages de points, sonar LIDAR